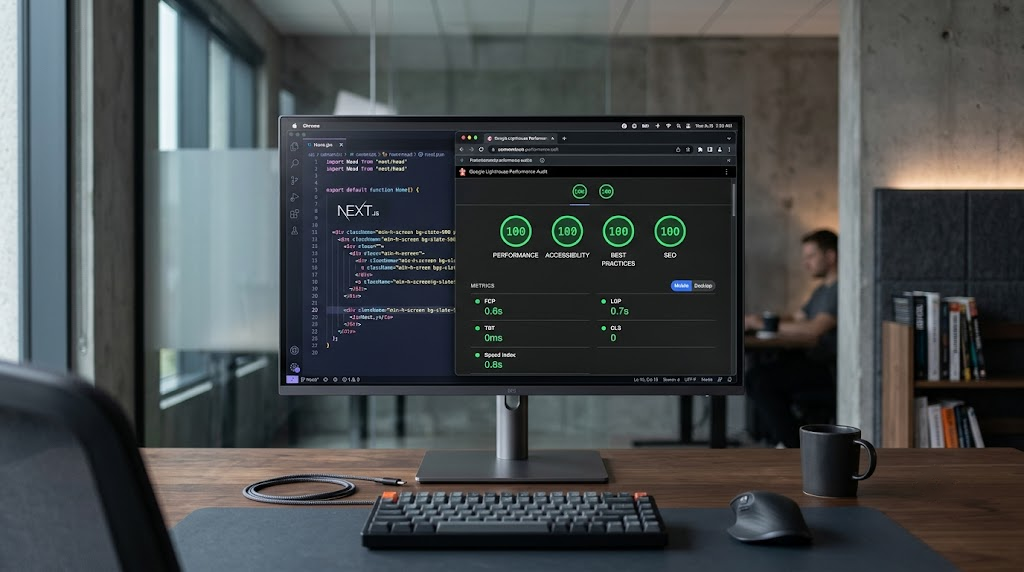
Your engineering team just shipped a brand new, visually stunning corporate website. The repository is pristine, the JavaScript components are highly modular, and the CSS file is completely minified. Your developers declare it a masterpiece of clean code, yet three months post-launch, your organic impressions in Google Search Console are completely flatlining.
This is the hidden crisis of modern digital production. Clean code is an internal operational standard for maintainability, but it does not equal automatic search visibility.
Search crawlers do not care how elegant your variable naming conventions are inside your GitHub repository. They care about document object model depth, script execution blockages, rendering logic, and server-side response times. Let us look past the usual developer assurances and dissect the exact engineering mechanics required to turn standard code into an enterprise lead generation asset.
Implementing SEO-friendly web development practices requires a shift from client-side rendering dependency to hybrid server architectures like Next.js or Laravel. To ensure visibility in modern generative search environments, engineering teams must prioritize native semantic HTML structures, automated JSON-LD schema injection, and aggressive Core Web Vitals optimization over visual builder configurations. This direct structural configuration allows search engines and large language models to accurately index and retrieve your enterprise data.
The Core Disconnect Between Clean Code and Search Crawlers
Developers are trained to write code that human engineering teams can easily read, scale, and debug. They look at architectural design patterns, separation of concerns, and component reusability. While these elements keep your technical debt low, they frequently conflict with how search engine bots parse a page.
The JavaScript Hydration Tax
Modern frontend web engineering relies heavily on single-page application frameworks. While building an interface completely in client-side React or Vue.js creates a smooth desktop user experience, it forces search engines to expend massive computing resources to view your content.
When a bot hits a client-side rendered page, it initially sees an empty HTML shell containing a single root script tag. The bot must spin up a secondary rendering engine to download, execute, and hydrate the JavaScript before it can read your text, headings, or internal links.
Google explicitly details their two-stage indexation pipeline where JavaScript execution is queued until processing resources become available. If your code delays rendering by even two seconds due to heavy main-thread execution, a crawler may leave before your primary content is visible. This resource limitation is why relying solely on standard client-side frameworks actively hidden damages your organic reach.
DOM Bloat from Nested Components
Clean code often uses deeply nested components to maintain strict visual modularity. However, when these components compile into production code, they can generate an incredibly deep Document Object Model.
An excessive DOM depth forces a crawler to expend more memory and processing cycles parsing the structural tree of your webpage. When a search engine’s parser hits thousands of nested wrapper tags, its crawling efficiency drops sharply, directly reducing your overall indexing budget across massive multi-page corporate sites.
Shifting Stacks: Deploying Hybrid Frameworks for Organic Dominance
To successfully implement true SEO-friendly web development practices, your core technology stack must be chosen based on rendering capability rather than developer convenience. Standard client-side rendering is built for private web applications behind a login screen, not for public B2B marketing engines designed to capture high-intent buyer traffic.
[Traditional Client Stack] -> Initial Request -> Empty HTML -> Download JS -> Hydrate DOM -> Crawler Time-Out
[BetaTech Hybrid Stack] -> Initial Request -> Edge-Rendered HTML Served -> Instant Indexation & Execution
Next.js and Static Site Generation (SSG)
For B2B marketing engines and corporate websites, we utilize Next.js combined with Tailwind CSS for frontend construction. Next.js addresses the JavaScript rendering issue by moving compilation away from the user’s browser and onto the server or build environment.
Through Static Site Generation, your code is pre-rendered into static HTML, CSS, and minimal JavaScript at the build level. When Googlebot requests a page, the server instantly delivers a fully formed document that can be indexed immediately on the first pass, with no secondary rendering pipeline required.
For dynamic corporate web assets that change frequently, Incremental Static Regeneration allows specific pages to update in the background without requiring a full rebuild of the entire application deployment.
[INTERNAL LINK: custom web application development solutions → web development services]
Laravel for Complex Relational Implementations
When a client project requires intricate backends, custom portals, or deep relational databases, we shift the engineering focus to Laravel. As a server-side framework, Laravel builds the HTML document directly on the server before dispatching it across a Content Delivery Network.
This architecture guarantees that all database entries, product catalogs, and programmatic landing pages are fully visible to search crawlers without any client-side layout shifts. Pairing Laravel with a lightweight utility-first styling utility like Tailwind CSS completely eliminates the structural overhead common in old-school enterprise content management systems.
Core Web Vitals Optimization at the Code Level
Google’s page experience metrics are not arbitrary ranking signals; they are direct measurements of how effectively your site runs on limited consumer hardware and mobile connections. True SEO-friendly web development practices treat these performance requirements as absolute hardware limits.
Largest Contentful Paint (LCP) Fixes
Largest Contentful Paint measures how long it takes for the primary structural asset of a web page to render on screen. In 2026, if your LCP takes longer than 2.5 seconds, your site is actively restricted from top-tier search visibility.
[LCP Lifecycle Timeline]
0.0s -> TTFB (Time to First Byte)
1.2s -> First Contentful Paint
2.1s -> Target LCP Achieved (Hero Element Rendered)
2.5s+ -> Critical Ranking Degradation Threshold
To optimize this layout milestone, developers must carefully prioritize asset delivery:
- Hero Image Preloading: Hero graphics must use explicit preloading instructions in the HTML document head, bypassing standard lazy-loading scripts.
- CSS Extraction: Critical inline styling required to render above-the-fold layout blocks must be injected directly into the HTML document, preventing additional round-trip asset requests.
- Asynchronous Script Execution: Non-critical assets, including analytics packages, tracking scripts, and heatmaps, must be deferred or set to execute asynchronously to completely clear the browser’s main thread during initial page load.
Eliminating Cumulative Layout Shift (CLS)
Cumulative Layout Shift measures visual instability during page initialization. A poor CLS score directly breaks user interaction and signals sloppy engineering to search crawlers.
This issue is entirely prevented by applying explicit aspect ratio properties directly to all graphical elements, video wrappers, and interactive banner placements within the source code. By defining these boundaries early, the browser reserves the exact structural layout dimensions on the page before the actual media asset is downloaded, completely eliminating sudden structural text jumps.
Semantic HTML vs. Component Bloat
The transition to visual site builders and component-driven engineering has led to a widespread degradation of basic semantic page architecture. Crawlers rely heavily on clean semantic tags to determine context, relative content importance, and page hierarchy.
[Inverted Div Bloat Structure]
<div class=”header-large”>Main Subject</div> -> No Crawler Hierarchical Weight
[Semantic Structural Pattern]
<h1>Main Subject</h1> -> Confirmed Primary Page Topic
When web applications rely on unsemantic component architecture, they hide the true meaning of the text behind custom wrapper tags that search engines struggle to understand. True SEO-friendly web development practices require returning to a native semantic layout structure:
- Use <h1> exclusively for the single primary subject of the page document.
- Organize your content subtopics sequentially using <h2>, <h3>, and <h4> structural elements, maintaining a logical data tree.
- Wrap your main navigation blocks inside a semantic <nav> element to clearly identify site architecture to crawlers.
- Isolate core text blocks inside structural <article> and <section> boundaries to separate unique ideas cleanly.
By ensuring your technical architecture follows native document models, you provide an optimized scannable document that search engine spiders and modern conversational AI discovery engines can read instantly with maximum accuracy.
Programmatic Schema: Structuring Data for 2026 Generative AI Engines
Search engine landscape changes in 2026 require optimizing your content for both traditional keyword indexing and advanced generative AI models. These models do not skim text like humans; they query relational databases and look for structured entities to build factual answers.
[Raw Text Content] -> AI Parsing Model (Inference Overhead)
[JSON-LD Schema Script] -> Automated Knowledge Graph Entry (Direct Answer Mapping)
To ensure your web properties are used as direct sources within AI search answers, your development pipeline must build automated structured data injection right into your core backend.
Automating Structural Microdata
Rather than relying on manual plugins that degrade site execution speed, we build custom structural data systems natively into the page templating pipeline. For instance, within a custom headless WordPress or Laravel setup, when a writer publishes an article, the system automatically builds and injects a deeply nested JSON-LD schema payload into the HTML page head.
JSON
{
“@context”: “https://schema.org”,
“@type”: “TechArticle”,
“headline”: “Why Most Clean Code Fails SEO-Friendly Web Development”,
“inLanguage”: “en-US”,
“author”: {
“@type”: “Person”,
“name”: “Md Mejbahul Alam”,
“jobTitle”: “SEO Manager”,
“worksFor”: {
“@type”: “Organization”,
“name”: “BetaTech LLC”
}
}
}
This automated structure clearly defines the relationships between the author, the corporate entity, the primary topic, and the underlying code components. It leaves zero room for semantic interpretation errors, allowing web crawlers to instantly confirm your expertise and use your structural metrics as trusted sources across global knowledge graphs.
Technical Discovery Call FAQ
Why does our fast desktop site fail mobile search performance checks?
Desktop computers hide poor code execution speeds through sheer raw computing power, multi-threaded processors, and stable high-speed office connections. Mobile search engines test your code using simulated lower-tier mobile processors running on throttled mobile networks. If your site depends on loading massive JavaScript component bundles to display basic text layouts, the mobile processor will choke during script interpretation, causing a massive delay in your Core Web Vitals metrics.
Can we convert an existing unoptimized visual framework into a high-performance site?
While basic assets can be optimized by compressing media files, implementing aggressive edge caching, and delaying non-critical tracking scripts, you cannot fully fix an unoptimized core framework. If the underlying architecture relies on a visual builder that generates excessive code wrappers and forces full-page client-side rendering, the most cost-effective solution is to decouple your frontend. Migrating the design to a fast framework like Next.js removes the technical debt and delivers long-term traffic stability.
How does our choice of database structure impact search crawl efficiency?
Your database structure directly dictates your Time to First Byte (TTFB). If your backend relies on unindexed, highly nested relational queries to compile a web page, your origin server will take too long processing requests before sending the first byte of data back to the browser. If your TTFB exceeds 600 milliseconds, search bots will throttle their crawl frequency across your site, directly reducing how often your deep-tier programmatic landing pages get re-indexed for keyword updates.
Do custom API integrations slow down our page rendering times?
If your custom APIs are called synchronously on the client side during page initialization, they will completely block the browser’s main execution thread, causing severe Largest Contentful Paint delays. At BetaTech, we protect performance by isolating external API requests to the server level during static site builds, or by processing them asynchronously after the primary layout has fully loaded. This technique keeps your user interface incredibly responsive while ensuring search bots can read your text without blocking on third-party data servers.
The Final Blueprint: Partner with BetaTech
Choosing between generic visual setups and purpose-engineered, search-optimized web architecture is the deciding factor in whether your digital presence drives growth or sits invisible on page three. High-performance B2B sites require an integrated approach where advanced engineering logic and technical search optimization are built into the initial system design, not patched on right before launch.
At BetaTech, we operate completely free from traditional corporate agency fluff, bloated retainers, and empty marketing promises. We look at your actual engineering requirements, clear out execution bottlenecks, and construct scalable web architectures designed to generate leads and hold top rankings.
Our unique global structure gives your business a direct competitive advantage. We are a tightly integrated family of 8 cross-functional technical specialists spanning Bangladesh and the United States. Led by our key players—including Adnan Shawkat (CEO), Miraj Ahmed (Operations), Sharmin Salma Tisha (CIO & Sr. Developer), and myself executing your technical indexing strategy—we operate on a 24/7 Continuous Development Cycle. While your regional operations sleep, our global squad continues coding, profiling, and optimizing your web assets around the clock. This ensures you get exceptionally fast launch timelines, continuous site monitoring, and precise execution without traditional US agency overhead.
Connect with our technical team today. Schedule an Engineering Architecture Session with BetaTech to audit your performance stack and map out your path to high-intent conversion growth.